MASTER NOTES - NEURAL NETWORKS AND BACKPROPAGATION¶
Introduction¶
Timestamp: 00:00:00¶
What training a Neural Network looks like under the hood. By the end of this, we will be able to define and train a Neural Net, to see how it works in an intuitive level.
Micrograd overview¶
Timestamp: 00:00:25¶
Micrograd - is basically a tiny Autograd engine.
Autograd engine - short for Automatic Gradient, it implements backpropagation.
Backpropagation - is an algorithm which allows you to efficiently evaluate a gradient of some kind of a loss function with respect to the weights of a neural network. What that allows us to do is that we can iteratively tune the weights of that neural network to -> minimize the loss function, and therefore -> improve the accuracy of the neural network.
So, Backpropagation would be at the Mathematical core of any modern deep neural network library like PyTorch or Jax.
Functionality of Micrograd explained - micrograd-functionality
So ultimately, Micrograd is all you need to train a Neural Network. Everything else is just for efficiency.
Derivative of a simple function with one input¶
Timestamp: 00:08:08¶
A Simple working example was done to explain the working/calculation of a Derivative of a function. Added to Jupyter notebook
Derivative of a function with multiple inputs¶
Timestamp: 00:14:12¶
Added three more scalar inputs a, b, c. To the function d = a*b + c
The derivative of the final function d was seen wrt to each of them, and the behavior was observed.
Added to Jupyter notebook
(Although I understood how the math of how this worked, I'm still not fully aware of how this explains the "behavior of the derivative" as he mentions in the end 🤔)
Starting the core Value object of micrograd and its visualization¶
Timestamp: 00:19:09¶
Now, Neural Networks are these massive mathematical expressions. So, we will be needing some data structures to maintain these expressions. Which is what we will be building.
- Initial explanation from value-object-creation
- From 22:45 to 24:54 - Visualization: Explained in value-object-creation (Visualization of the expression)
- From 24:55 to 29:01 - Generating the visual graphs in value-object-creation (Visualization of the expression continued)
- value-object-creation (SUMMARY & WHAT TO DO NEXT)
Manual backpropagation example #1: simple expression¶
Timestamp: 00:32:10¶
A grad variable has been declared in the Value object. Which will contain the derivative of L w.r.t each of those leaf nodes.
Manual Backpropagation for L, f and g in the expression: Notebook We have basically done 'gradient checks' here. Gradient check is essentially where we are deriving the backpropagation of an expression, by checking all of it's intermediate nodes.
(VERY IMPORTANT PART) From 38:06 - This step will be the crux of backpropagation. This will be THE MOST IMPORTANT NODE TO UNDERSTAND. If we understand the gradient of this node, then we understand all of backpropagation and all of training of NN!! -> crux-node-backpropagation
Preview of a single optimization step¶
Timestamp: 00:51:10¶
Here, we are just trying to nudge the inputs to make our L value go up.
Now, we modify the weights of the leaf nodes (because that is what we usually have control over) slightly towards more positive direction and see how that affects L (in a more positive direction).
So if we want L to increase, we should nudge the nodes slightly towards the gradient (eg, a should increase in the direction of the gradient, in step size) Notebook
This is basically one step of the optimization that we ended up running. And really these gradient values calculated, give us some power, because we know how to influence the final outcome. And this will be extremely useful in training neural nets (which we will see soon :) )
Manual backpropagation example #2: a neuron¶
Timestamp: 00:52:52¶
Here, we are going to backpropagate through a neuron.
So now, we want to eventually build out neural networks. In the simpler stage, these are multi-level perceptrons. For example: We have a two layer neural net, which contains two hidden (inner) layers which is made up of neurons which are interconnected to each other.
Now, biologically neurons are obviously complicated devices, but there are simple mathematical models of them. neurons-explaination Notebook
From 1:00:38, we'll see the tanh function in action and then the implementation of backpropagation (Manual backpropagation method)
If you want to influence the final output, then you should increase the bias. Only then the tanh will squash the final output and flat out to the value 1 (As seen in the graph. Notebook
Implementing the backward function for each operation¶
Timestamp: 01:09:02¶
We will be creating functions which would calculate the backpropagation i.e. the gradient values by itself! As the name of the chapter suggests, we'll be implementing it in each of the operations, like for '+', ' * ', 'tanh'
Note on the '_ backward' function created:
- In the operation functions, we had created 'out' values which are an addition to/combination of the 'self' and 'other' values.
- Therefore we set the 'out._ backward' to be the function that backpropagates the gradient.
- Therefore we define what should happen when that particular operation function (Eg, add, mul) is called, inside the 'def backward()'
Implementing the backward function for a whole expression graph¶
Timestamp: 01:17:32¶
Instead of calling the '_ backward' function each time, we are creating it as a function in the Value object itself.
Now, we also need to make sure that all the nodes have been accessed and forward pass through. So, we have used a concept called 'topological sort' where all the nodes are accessed/traversed in the same/one direction (either left-to-right or vice-versa) See the image here
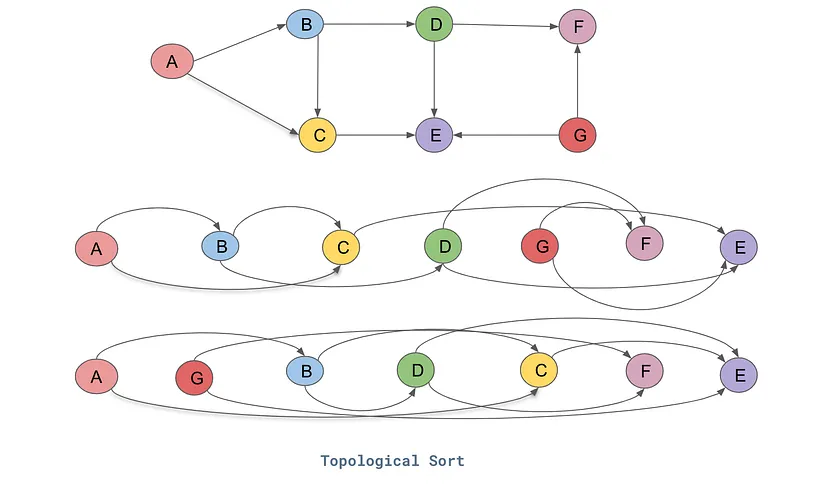{kind=link}
Therefore, we are adding the code for it, where it ensures that all the nodes are accessed at least once (and only stored once) and the node is only stored after/when all of it's child nodes are accessed and stored. This way we know we have traversed through the entire graph.
Once all the nodes have been topologically sorted, we then reverse the nodes order (Since we are traversing it from left to right i.e. input to output, we are reversing it, so that the gradients are calculated. As we have done previously in our examples) call the '_ backward' function to perform backpropagation from the output. Notebook
And that was it, that was backpropagation! (Atleast for one neuron :P)
Fixing a backprop bug when one node is used multiple times¶
Timestamp: 01:22:28¶
Resolving a bug, where if there are multiple same nodes, then the calculation of the gradient isn't happening correctly as it considers both those separate nodes as a single node. Notebook
Solution was to append the gradient values.
Breaking up a tanh, exercising with more operations¶
Timestamp: 01:27:05¶
So far we had directly made a function for tanh, because we knew what it's derivative be.
So now we'll be trying to expand it into its other derivative form which contains exponents.
Therefore we are able to perform more operations such as exponents, division and subtraction (Therefore making it a good exercise)
Entire detailed explanation in: expanding-tanh-and-adding-more-operations
Apart from showing that we can do different operations. We also want to show that the level up to which we want to implement the operations is up to us.
To explain, in our example- It can directly be 'tanh' or break it down into the expressions of exp, divide and subtract.
As long as the know the backward pass of that operation, it can be implemented in anyway.
Doing the same thing but in PyTorch: comparison¶
Timestamp: 01:39:31¶
Now we are going to see how we can convert our code into PyTorch (syntax?). Normally PyTorch is used during production. Comparison and Explanation: pytorch-comparision
Building out a neural net library (multi-layer perceptron) in micrograd¶
Timestamp: 01:43:55¶
We'll be building everything we have learnt till now, into a proper Neural Network type in code, using PyTorch. Everything will be broken down properly in - multi-layer-perceptron So, forward pass implementation has been done. Next we will also implement the backpropagation part.
Creating a tiny dataset, writing the loss function¶
Timestamp: 01:51:04¶
We made like a list of input values and then a list of values we want as an output. Saw how the pred values turn out. Calculated the loss function for individual as well as entire, to see how it is affecting.
Also note: I had added __radd__() to the Value object to handle the case of int adding with a Value.
Detailed step by step process is in the notebook
Collecting all of the parameters of the neural net¶
Timestamp: 01:57:56¶
Here we are going to write some convenience code, so that we can gather all the parameters of the neural net and work on all of them simultaneously. We'll be nudging them by a small amount based on the gradient differentiation.
That's where we are adding parameters functions. Now another reason why we are doing this, is that even the n function (Neuron function) in PyTorch also provides us with parameters which we can use. Therefore, we are declaring one for our MLP too. So there is the parameters of tensors and for us it's parameters of scalars. Notebook
Doing gradient descent optimization manually, training the network¶
Timestamp: 02:01:12¶
We are basically performing 'Gradient Descent' here, by slightly nudging the values of the inputs to see how it can help to reduce the loss function. Notebook
(I didn't exactly get the predicted output as excepted, but hey this is just the beginning. We'll see where we get from here :) )
And that was the end of the first lecture! See you in the next one ;)